Most people know the concepts of SSL, but not the gory details. By using Facebook as a walkthrough example, I’m going to discuss how it works from the browser’s viewpoint, and how it impacts latency to your site. BTW, this is not intended as a criticism of Facebook – they’re doing all the right things to make sure your data is encrypted and authenticated and fast. The failures highlighted here are failures of a system that wasn’t designed for speed.
Fetching the Certificate
When you first connect to a SSL site, the client and server use the server’s public key to exchange a secret which will be used to encrypt the session. So the first thing the client needs to do is to get the server’s public key. The public key is sent as part of the SSL Server Hello message. When we look at the Server Hello Message from Facebook, we see that it sent us a Certificate which was 4325 bytes in size. This means that before your HTTP request even gets off your computer, the server had to send 4KB of data to the client. That’s a pretty big bundle, considering that the entire Facebook login page is only 8.8KB. Now, if a public key is generally only 1024 or 2048 bits, with elliptic curve keys being much smaller than that, how did Facebook’s certificate mushroom from 256 to 4325 bytes? Clearly there is a lot of overhead. More on this later.
Trusting the Certificate
Once the browser has the server’s certificate, it needs to validate that the certificate is authentic. After all, did we really get Facebook’s key? Maybe someone is trying to trick us. To deal with this, public keys are always transferred as part of a certificate, and the certificate is signed by a source, which needs to be trusted. Your operating system shipped with a list of known and trusted signers (certificate authority roots). The browser will verify that the Facebook certificate was signed by one of these known, trusted signers. There are dozens of trusted parties already known to your browser. Do you trust them all? Well, you don’t really get a choice. More on this later.
But very few, if any, certificates are actually signed by these CA’s. Because the Root CA’s are so important to the overall system, they’re usually kept offline to minimize chances of hackery. Instead, these CAs periodically delegate authority to intermediate CAs, when then validate Facebook’s certificate. The browser doesn’t care who signs the certificate, as long the chain of certificates ultimately flows to a trusted root CA.
And now we can see why Facebook’s Certificate is so large. It’s actually not just one Certificate – it is 3 certificates rolled into one bundle:
The browser must verify each link of the chain in order to authenticate that this is really Facebook.com.
Facebook, being as large as they are, would be well served by finding a way to reduce the size of this certificate, and by removing one level from their chain. They should talk to DigiSign about this immediately.
Verifying The Certificate
With the Facebook Certificate in hand, the browser can almost verify the site is really Facebook. There is one catch – the designers of Certificates put in an emergency safety valve. What happens if someone does get a fraudulent certificate (like what happened last month with Comodo) or steal your private key? There are two mechanisms built into the browser to deal with this.
Most people are familiar with the concept of the “Certificate Revocation List†(CRL). Inside the certificate, the signer puts a link to where the CRL for this certificate would be found. If this certificate were ever compromised, the signer could add the serial number for this certificate to the list, and then the browser would refuse to accept the certificate. CRLs can be cached by the operating system, for a duration specified by the CA.
The second type of check is to use the Online Certificate Status Protocol (OCSP). With OCSP, instead of the browser having to download a potentially very large list (CRL), the browser simply checks this one certificate to see if it has been revoked. Of course it must do this for each certificate in the chain. Like with CRLs, these are cacheable, for durations specified in the OCSP response.
In the Facebook.com example, the DigiCert certificates specify an OCSP server. So as soon as the browser received the Server Hello message, it took a timeout with Facebook and instead issued a series of OCSP requests to verify the certificates haven’t been revoked.
In my trace, this process was quick, with a 17ms RTT, and spanning 4 round-trips (DNS, TCP, OCSP Request 1, OCSP Request 2), this process took 116ms. That’s a pretty fast case. Most users have 100+ms RTTs and would have experienced approximately a ½ second delay. And again, this all happens before we’ve transmitted a single byte of actual Facebook content. And by the way, the two OCSP responses were 417 bytes and 1100 bytes, respectively.
Oh but the CDN!
All major sites today employ Content Delivery Networks to speed the site, and Facebook is no exception. For Facebook, the CDN site is “static.ak.facebook.comâ€, and it is hosted through Akamai. Unfortunately, the browser has no way of knowing that static.ak.facebook.com is related to facebook.com, and so it must repeat the exact same certificate verification process that we walked through before.
For Facebook’s CDN, the Certificate is 1717 bytes, comprised of 2 certificates:
Unlike the certificate for facebook.com, these certificates specify a CRL instead of an OCSP server. By manually fetching the CRL from the Facebook certificate, I can see that the CRL is small – only 886 bytes. But I didn’t see the browser fetch it in my trace. Why not? Because the CRL in this case specifies an expiration date of July 12, 2011, so my browser already had it cached. Further, my browser won’t re-check this CRL until July, 4 months from now. This is interesting, for reasons I’ll discuss later.
Oh but the Browser Bug!
But for poor Facebook, there is a browser bug (present in all major browsers, including IE, FF, and Chrome) which is horribly sad. The main content from Facebook comes from www.facebook.com, but as soon as that page is fetched, it references 6 items from static.ak.facebook.com. The browser, being so smart, will open 6 parallel SSL connections to the static.ak.facebook.com domain. Unfortunately, each connection will resend the same SSL certificate (1717 bytes). That means that we’ll be sending over 10KB of data to the browser for redundant certificate information.
The reason this is a bug is because, when the browser doesn’t have certificate information cached for facebook.com, it should have completed the first handshake first (downloading the certificate information once), and then used the faster, SSL session resumption for each of the other 5 connections.
Putting It All Together
So, for Facebook, the overall impact of SSL on the initial user is pretty large. On the first connection, we’ve got:
- 2 round trips for the SSL handshake
- 4325 bytes of Certificate information
- 4 round trips of OCSP validation
- 1500 bytes of OCSP response data
Then, for the CDN connections we’ve got:
- 2 round trips for the SSL handshake
- 10302 bytes of Certificate information (1717 duplicated 6 times)
The one blessing is that SSL is designed with a fast-path to re-establish connectivity. So subsequent page loads from Facebook do get to cut out most of this work, at least until tomorrow, when the browser probably forgot most of it and has to start over again.
Making it Better
OCSP & CRLs are broken
In the above example, if the static.ak.facebook.com keys are ever compromised, browsers around the planet will not notice for 4 months. In my opinion, that is too long. For the OCSP checks, we cache the result for usually ~7 days. Having users exposed to broken sites for 7 days is also a long time. And when Comodo was hacked a month ago, the browser vendors elected to immediately patch every browser user on the planet rather than wait for the OCSP caches to expire in a week. Clearly the industry believes the revocation checking is broken when it is easier to patch than rely on the built-in infrastructure.
But it is worse than that. What does a browser do when if the OCSP check fails? Of course, it proceeds, usually without even letting the user know that it has done so (heck, users wouldn’t know what to do about this anyway)! Adam Langley points this out in great detail, but the browsers really don’t have an option. Imagine if DigiCert were down for an hour, and because of that users couldn’t access Facebook? It’s far more likely that DigiCert had downtime than that the certificate has been revoked.
But why are we delaying our users so radically to do checks that we’re just going to ignore the result of if they fail anyway? Having a single-point-of-failure for revocation checking makes it impossible to do anything else.
Certificates are Too Wordy
I feel really sorry for Facebook with it’s 4KB certificate. I wish I could say theirs was somehow larger than average. They are so diligent about keeping their site efficient and small, and then they get screwed by the Certificate. Keep in mind that their public key is only 2048bits. We could transmit that with 256B of data. Surely we can find ways to use fewer intermediate signers and also reduce the size of these certificates?
Certificate Authorities are Difficult to Trust
Verisign and others might claim that most of this overhead is necessary to provide integrity and all the features of SSL. But is the integrity that we get really that much better than a leaner PGP-like system? The browser today has dozens of root trust points, with those delegating trust authority to hundreds more. China’s government is trusted by browsers today to sign certificates for google.com, or even facebook.com. Do we trust them all?
A PGP model could reduce the size of the Certificates, provide decentralization so that we could enforce revocation lists, and eliminate worries about trusting China, the Iranian government, the US government, or any dubious entities that have signature authority today.
Better Browser Implementations
I mentioned above about the flaw where the browser will simultaneously open multiple connections to a single site when it knows it doesn’t have the server’s certificate, and thus redundantly download potentially large certs. All browsers need to be smarter.
Although I expressed my grievances against the OCSP model above, it is used today. If browsers continue to use OCSP, they need to fully implement OCSP caching on the client, they need to support OCSP stapling, and they need to help push the OCSP multi-stapling forward.
SSL Handshake Round Trips
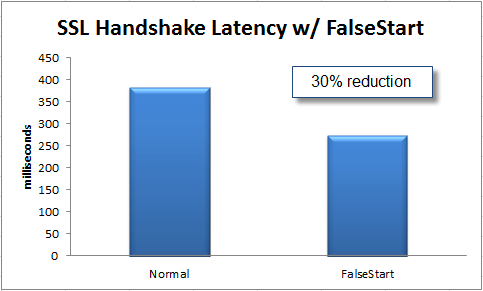
The round trips in the handshake are tragic. Fortunately, we can remove one, and Chrome users get this for free thanks to SSL False Start. False Start is a relatively new, client-side only change. We’ve measured that it is effective at removing one round trip from the handshake, and that it can reduce page load times by more than 5%.
Hopefully I got all that right, if you read this far, you deserve a medal.