My friend Marc Orchant has taken the same path as me!
Category: Technology
Jettisoned Facebook
Facebook has been a completely unnecessary part of my life for the past few months. Today, it is no longer.
Why? I got an ad which read, “Leaving Google? …” from First Round Capital. OK – that’s neat; Josh is a clever guy! But, that is not what I want. I don’t mind seeing the ad, but I don’t know what information about me Facebook shares with it’s advertisers. Fortunately, I’ve been a lot less revealing with my information than some people are. But clearly I already said too much. Thank god they didn’t have any credit cards!
Bye!
Semaphores vs Events Showdown
I enjoy asking an interview question about threading and queues. Candidates usually attempt to solve the problem using one of two Windows synchronization primitives – either the Event or the Semaphore. Sadly, I see a lot more attempts using Events than Semaphores. Sometimes, I’ll ask, “which is faster on Windows, a semaphore or an event?” The answer is “it depends”, but most people don’t say that. Anyway, it is my opinion that Events are awful from a programming model as well as from a performance standpoint. Let’s find out.
To find out, I had to create a little benchmark. Of course, any benchmark is contrived, and this one is no different. Lets create a set of N producers and N consumers putting and getting from a queue. Then let’s implement basically the same queue using each of 3 types: a semaphore based queue, an event based queue (manual reset events) and an event based queue (auto reset events).
I ran each of these 3 algorithms with 8 concurrent consumers and producers through 20,000 iterations (I did 5 samples, threw out the hi/lo, etc etc):
| Latency | Max Queue Depth | |
| Semaphore | 284.6ms | ~10K |
| Event (auto-reset) | 456.2ms | ~150K |
| Event (manual reset) | 297.2ms | ~10K |
So the conclusion is that for this test, events and semaphores are pretty close. The semaphore does provide a slight (<10%) performance improvement over the event.
But it also shows that there is clearly a right and wrong way to use the event; auto-reset being bad, and manual-reset being good. I suspect this is basically due to the benchmark itself; the benchmark is greedy – the producers all add items to the queue as quickly as possible. Since usually there is something on the queue, the manual reset event doesn’t need to clear the event nearly as often. I weakly attempted to add a delay to mix things up, but even a modest delay (1ms) basically makes all of these algorithms behave identically unless you crank the thread count through the roof.
Next, I decided to increase the thread count of producers and consumers to 32 instead of 8. Now we get this:
| Latency | Max Queue Depth | |
| Semaphore | 949.6ms | ~20K |
| Event (auto-reset) | 1615.6ms | ~600K |
| Event (manual reset) | 621.8ms | ~165K |
Now all you Event fans will tell me to eat crow, clearly the Event is faster, right? Not quite! In this case, the manual-reset event code is cheating. Each time you add a single element to the queue, many consumers awaken because they all see the event as set; since its a greedy benchmark, this is like predicting the future – that an element will be ready by the time the consumer gets through the lock. It’s coincidental to the benchmark that it works. But it is interesting to see. Also note the max queue length now shows a different problem. The semaphore is reasonably “fair” compared to the Event based implementations.
I still dislike events, however. And if you don’t yet agree, take a look at the code. The Semaphore code is incredibly simple compared to the Event based code. (Is there a simplification I could have made?) There is no doubt in my mind that most experienced programmers will botch the Event based algorithm. I’m reasonably confident these solutions are correct, I wouldn’t be completely surprised if some smart reader posts that my implementation is flawed too.
There is one place where Events are useful; if you have a need for synchronization which changes only once (e.g. from set to unset), events are pretty cool. In the driver for this test program, I used an event to start the test after warming up all the threads. Events are great for that. Just don’t use them in loops ever!
Lastly, I’m sure I left out something important. If you’ve got another idea about this, please post a comment! But don’t bark about my lack of error checking or huge queue lengths. I did that on purpose.
Here is the source code to the Semaphore-based Queue:
#pragma once
#include <assert.h>
class QueueUsingSemaphore {
public:
QueueUsingSemaphore(int max_items) :
head_(0),
tail_(0),
count_items_(0),
max_items_(0),
queue_max_(max_items) {
items_ = new int[queue_max_];
InitializeCriticalSection(&lock_);
semaphore_ = CreateSemaphore(NULL, 0, queue_max_, NULL);
}
~QueueUsingSemaphore() {
delete items_;
assert(head_ == tail_);
printf("Max was %dn", max_items_);
}
int Get() {
int rv;
WaitForSingleObject(semaphore_, INFINITE);
EnterCriticalSection(&lock_);
assert(head_ != tail_);
rv = items_[head_];
head_ = (++head_) % queue_max_;
LeaveCriticalSection(&lock_);
return rv;
}
void Put(int val) {
EnterCriticalSection(&lock_);
items_[tail_] = val;
tail_ = (++tail_) % queue_max_;
assert(head_ != tail_); // Queue is overflowing.
int count = tail_ - head_;
if (count<0) count += queue_max_;
if (count > max_items_) { max_items_ = count; }
LeaveCriticalSection(&lock_);
ReleaseSemaphore(semaphore_, 1, NULL);
}
private:
HANDLE semaphore_;
CRITICAL_SECTION lock_;
int *items_;
int head_;
int tail_;
int count_items_;
int max_items_;
int queue_max_;
};
Here is the Event based code (manual reset):
#pragma once
#include <assert.h>
class QueueUsingManualEvent {
public:
QueueUsingManualEvent(const int max_items) :
head_(0),
tail_(0),
count_items_(0),
max_items_(0),
queue_max_(max_items) {
items_ = new int[queue_max_];
InitializeCriticalSection(&lock_);
event_ = CreateEvent(NULL, TRUE, FALSE, NULL); // Manual-reset event.
}
~QueueUsingManualEvent() {
delete items_;
assert(head_ == tail_);
printf("Max was %dn", max_items_);
}
int Get() {
bool got_one = false;
int rv;
while (!got_one) {
WaitForSingleObject(event_, INFINITE);
// Note: it is possible to get here and have the queue be empty.
EnterCriticalSection(&lock_);
if (head_ == tail_) {
LeaveCriticalSection(&lock_);
continue;
}
got_one = true;
rv = items_[head_];
head_ = (++head_) % queue_max_;
if (head_ == tail_)
ResetEvent(event_); // The queue is now empty.
LeaveCriticalSection(&lock_);
}
return rv;
}
void Put(int val) {
EnterCriticalSection(&lock_);
items_[tail_] = val;
tail_ = (++tail_) % queue_max_;
assert(head_ != tail_); // Queue is overflowing.
int count = tail_ - head_;
if (count<0) count += queue_max_;
if (count > max_items_) { max_items_ = count; }
// It's tempting to move this outside the lock. However,
// unlike the semaphore, this cannot be moved outside the
// lock because the threads are intentionally racing
// on the event notification.
SetEvent(event_);
LeaveCriticalSection(&lock_);
}
private:
HANDLE event_;
CRITICAL_SECTION lock_;
int *items_;
int head_;
int tail_;
int count_items_;
int max_items_;
int queue_max_;
};
Here is the source to the driver code:
#pragma once
#include "queue_semaphore.h"
#include "queue_event.h"
#include "queue_event_manual.h"
class Driver {
public:
Driver() :
queue_(kMaxItems) {
start_event_ = CreateEvent(NULL, TRUE, FALSE, NULL);
}
void StartThreads() {
for (int i=0; i<kMaxProducers; i++)
threads_[i] = CreateThread(NULL, 0, ProducerMain, this, 0, 0);
for (int i=0; kMaxConsumersi++)
threads_[kMaxProducers + i] = CreateThread(NULL, 0, ConsumerMain, this, 0, 0);
Sleep(500); // Let the threads get ready.
start_ticks_ = GetTickCount();
SetEvent(start_event_);
}
void WaitForFinish() {
for (int i=0; i<kMaxProducers + kMaxConsumers; i++)
WaitForSingleObject(threads_[i], INFINITE);
stop_ticks_ = GetTickCount();
}
int TimeTaken() {
return stop_ticks_ - start_ticks_;
}
void Producer() {
WaitForSingleObject(start_event_, INFINITE);
for(int i=0; i<kMaxIterations; i++)
queue_.Put(i);
}
void Consumer() {
WaitForSingleObject(start_event_, INFINITE);
for (int i=0; i<kMaxIterations; i++)
int x = queue_.Get();
}
private:
static DWORD WINAPI ProducerMain(void *self) {
Driver* driver = static_cast(self);
driver->Producer();
return 0;
}
static DWORD WINAPI ConsumerMain(void *self) {
Driver* driver = static_cast(self);
driver->Consumer();
return 0;
}
static const int kMaxProducers = 32;
static const int kMaxConsumers = 32;
static const int kMaxIterations = 20000;
static const int kMaxItems = (kMaxProducers + kMaxConsumers)*kMaxIterations;
HANDLE start_event_;
//QueueUsingSemaphore queue_;
//QueueUsingEvent queue_;
QueueUsingManualEvent queue_;
HANDLE threads_[kMaxProducers + kMaxConsumers];
int start_ticks_;
int stop_ticks_;
};
My Favorite Geek Resources
If you write a lot of software and have your own stuff that you host and tinker with, here are some recommendations:
1) ServerBeach! ServerBeach provides dedicated server hosting. Need a place to hack on perl, python, apache, and php? These guys have great bandwidth, great support, and zero downtime. I pay $99/mo. Checkout my uptime:
[mbelshe@s1]$ uptime
11:02:04 up 422 days, 3:32, 2 users, load average: 1.41, 1.07, 0.82
2) Code Project. This is just a great site for collecting articles about random coding topics, with concrete examples. I read the RSS feed daily. Sure, there are people that post weak articles, but reading this daily gets your mind thinking about topics you wouldn’t have otherwise considered.
Daunting Installers
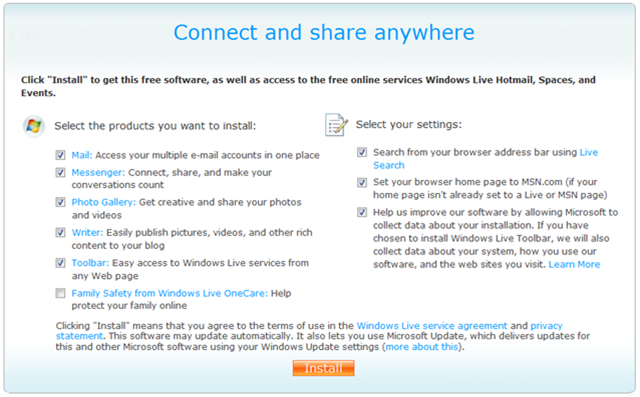 I read the news about the latest Windows Live Suite from Microsoft today. I hadn’t tried the “Family Safety OneCare” product, so I thought I’d give it a shot.
I read the news about the latest Windows Live Suite from Microsoft today. I hadn’t tried the “Family Safety OneCare” product, so I thought I’d give it a shot.
Then I clicked on the installer. (Click to enlarge)
Then I said, “ugh.”
I really just wanted to try OneCare. But the installer offers up 9 different checkboxes of “stuff” for me to download. This wouldn’t be a problem except the 8 of them are checked – requiring me to uncheck them. And, in the world’s most ironic part, the Windows Live OneCare product is the *only* one of the bunch which isn’t checked.
Am I too sensitive to unchecking boxes?
When They Take Away the Full RSS Feed…
This has happened a few times to me. I find a blog I enjoy, and I read it for some time. Maybe a year or more. Then, one day, the author of the blog stops posting full-article feeds. What do you do?
In my case, I have always stopped reading. There’s just too much content out there to go following every link. In order to follow a link, I need to be searching for something, and also be under the belief that the link will help me. When browsing through the day’s news, I am not searching for anything specific. So naturally, I won’t click the link.
This happened to me with some zdnet blogs a while ago (actually, I think they never published a full feed?), and this month it happened with Kawasaki’s blog. I sent a nice email to Guy – but we’ll see if he responds; I’m sure he gets a lot of junk.
What do you do? I bet few people follow the clicks.
Python’s Does Not Not Have a Not
 I’m new to Python; trying to write a little script. I need to use the “not” operator. At first, I tried the nearly universal ! operator. Syntax error – that’s not it. So I open my handy Python in a Nutshell book, and look up the operators (pg 36). Sure enough, ! is not one of them. Hmm. So, I look in the index for “not”. “not” is not there. Could it be that Python has not got a not?
I’m new to Python; trying to write a little script. I need to use the “not” operator. At first, I tried the nearly universal ! operator. Syntax error – that’s not it. So I open my handy Python in a Nutshell book, and look up the operators (pg 36). Sure enough, ! is not one of them. Hmm. So, I look in the index for “not”. “not” is not there. Could it be that Python has not got a not?
No, of course it does not not have a not. I found the answer on pg 50 – the not operator is aptly named “not” – e.g. “if not foo:”
Not funny? Not was not in the index!
What if Microsoft had conceded in 1997?
Today, Microsoft conceded on a number of points in their European anti-trust case. This is a huge turn for Microsoft, as it has battled this lawsuit since 2004. Stepping back in time, we all remember the 1997 US anti-trust case which led the way to a June 2000 order that Microsoft be broken up. That ruling was overturned in 2001, of course. But clearly, the last 10 years have been tough on Microsoft.
Microsoft is no longer the same company as in 1997. It clearly learned something.
In 1997, when accused of using its monopoly power to crush Netscape, Microsoft staunchly denied any wrongdoing. Microsoft claimed that the browser was not separable from the operating system, and Jim Allchin openly lied in court about it. (Ironically, Microsoft quietly made IE7 separate from the operating system).
The result of these actions was that the courts threw the book at Microsoft both in the US and in Europe. The courts didn’t like what Microsoft was doing, but worse, they didn’t like that Microsoft lied, protested, and refused to fix it. Microsoft was arrogant and the courts punished them.
In 2007, Microsoft was again accused of using monopolistic power – this time to push its Windows Live Search against that of rival Google. Google didn’t make much progress with this in the courts this time. Instead, Microsoft agreed to change Vista after the Google Complaint, and the judge was satisfied.
What happened here was simple. In 1997, Microsoft fought the allegations, and arrogantly denied any wrongdoing, when it was clearly not that simple. Because they refused to help fix the problem, the courts had no choice but to take action. Microsoft lost big.
Contrast this to 2007, where Microsoft realizes that there is no way to win by fighting. Instead, Microsoft pacifies the courts by agreeing to change and work with the system. This way, Microsoft decided how to change their products – and that is much easier than letting the courts decide. The approach worked fantastically. Judges naturally want disputes settled out of court and they look favorably on the party that is willing to compromise. Since the court really isn’t able to discern the subtleties of operating search APIs anyway, this is all too easy for the courts to agree to.
What if Microsoft had said, “Yes Judge Jackson, we’ll make IE removable” back in 1997? Microsoft would have won the browser market anyway. I doubt the Judge would have recommended a breakup.
The lesson to learn here is to know when to fight. Hubris will never be looked upon favorably. To any company that is ever in an anti-trust lawsuit in the future – learn from Microsoft. The only winning tactic is to compromise immediately, work with the courts and do everything you can to demonstrate good-faith resolution of the problem.
The Most Elegant Code
After years of debate about what makes readable code, its becoming clear to most developers that most of the time, the best code is also the shortest code. I’m not saying you should pretend it’s fortran and use variables like “i”, “k”, etc. Likewise, I’m definitely not arguing that you should strip comments! But, for any logical statement, if it can be reduced, it can be made better.
When you are trying to write something that has few loopholes or bugs, writing it more succinctly is often the way to do it. Further, by writing in the shortest form, code becomes similar, even if it didn’t come from the same author. Verbose code, on the other hand, has more opportunities for mistakes and more opportunities for logic flow that doesn’t do what you think it does.
Now that I’ve deceived you into thinking this is a post about software, I’ll tell you what it’s really about: lawyers. Software developers have only really existed for 30-40 years. Yet, in those few years, we’ve managed to figure this out – fewer lines of text is simpler. Lawyers, on the other hand, have existed for thousands of years and still haven’t figured out that the simplest, most truthful, and least buggy way to describe something is with fewer words. Perhaps lawyers seek not the truth.
The Internet Cuts The Middleman Again
Lots of people are writing about how major artists (Madonna, nine inch nails, radiohead, etc) are ditching their recording labels. They are instead opting to take their business to consumers on their own. This is so great, because everyone wins. Consumers get music for less and the musicians make more money. It’s awesome!
One of the great powers of the Internet is that you don’t need people that don’t build products. The Internet makes it so cheap and simple to get directly to your customers, that you don’t need someone else to do it for you.
Examples:
– Software Companies. 2 guys in a garage with no marketing, no sales, and no funding can build a product. (Lookout & lots of others)
– Authors. An amateur with a blog can garner the readership of millions without help from anyone. (TechCrunch, John Chow)
– IPOs. A company can go public without paying unreasonable royalties to underwriters by selling shares direct. (Google)
– Music. Musicians can sell their songs directly to the public.
In this world, there are two types of people. Those that build product (software products, physical goods, art, content, etc), and there are those that don’t build product (marketers, sales people, etc). The latter is becoming increasingly marginalized. Don’t get me wrong – there is definitely a need for salespeople and marketers. But thanks to the Internet, there is a decreasing need for them. I think this is great, because it makes us more productive as a society – everyone needs to learn to build something. It’s also a clear indicator that the Internet must always be free.